Simplifying Software Architecture Like a Superhero
A Lightweight Approach to Process Design with Eventual Consistency Using Event Sourcing in a Clustered Environment
I. Introduction
- Purpose and goals of this writing
- Benefits of adopting Event Sourcing principles for Process Design
- Overview of the Superhero Tool Chain
II. Understanding Event Sourcing
- What is Event Sourcing?
- Why use Event Sourcing in Process Design?
- How Event Sourcing works
- Benefits and drawbacks of Event Sourcing
III. Understanding Event Storming
- What is Event Storming?
- How to use Event Storming for Process Design
- Benefits of using Event Storming for Process Design
IV. Getting Started with the Superhero Tool Chain
- Explanation of the Superhero Tool Chain
- Creating a new project with the Superhero Core Framework
- Creating a new project with the Superhero Eventsource
- Notations regarding the Superhero Tool Chain
V. Implementing Event Sourcing like a Superhero
- Creating a Process Design flowchart from an Event Storming session
- Modeling the domain in the Superhero Core Framework
- Processing events using the Superhero Eventsource component
- Replay functionality using the Superhero Eventsource component
VI. Last Gasp
Introduction
Purpose and goals of this writing
The purpose of this writing is to provide a comprehensive guide to software architecture from the perspective of domain-driven design, Event Sourcing, CQRS, onion architecture, and other modeling approaches. We will cover the key concepts, principles, and best practices for these approaches, and provide examples and guidance for how to apply them in practice. Throughout this writing, we will use the Superhero Tool Chain to illustrate the concepts and provide practical guidance.
The Superhero Tool Chain is a lightweight and flexible solution for software architecture and Process Design using Event Sourcing. The tool chain includes a backend “core” framework that is built with Node.js, which provides a simple and efficient platform for building scalable and reliable lightweight software solutions. The Superhero Eventsource component is a key part of the tool chain, and is used to enable Event Sourcing and taking advantage of a clustered environment. The Superhero Eventsource component depends on Redis, a popular in-memory data store that is widely used as an in-memory storage solution.
We will begin by discussing the challenges and complexities of software architecture, and the importance of adopting a domain-driven design approach to ensure that software systems are aligned with business requirements. We will then introduce the concept of Event Sourcing, which is a technique for capturing all changes to an application’s state as a sequence of immutable events. We will explain how this approach enables simpler and more flexible Process Design, as well as improved auditability and traceability of data changes.
Next, we will discuss the benefits of using the Superhero Tool Chain, which has been specifically designed to provide a lightweight and simple solution for Process Design with eventual consistency in a clustered environment. We will explain how the tool chain provides a simple and efficient platform for building scalable and reliable software solutions, and how the Superhero Eventsource component enables Event Sourcing in a clustered environment.
In the following chapters, we will explore each of the different modeling approaches in detail, providing examples and guidance for how to apply them in practice using the Superhero Tool Chain. We will also provide guidance for how to build scalable and reliable software solutions in a clustered environment using Event Sourcing and the Superhero Tool Chain.
Benefits of adopting Event Sourcing principles for Process Design
In the field of software architecture, designing complex business processes can be a challenging task. Architects must ensure that the software accurately represents the business logic of the domain, while still being flexible enough to adapt to changing business needs. This becomes especially challenging when working with architectures that operate with eventual consistency.
Eventual consistency requires a different approach to software architecture and Process Design. Complex operations must be broken down into smaller, simpler steps, and each step must be executed in a consistent and predictable manner. This is where Event Sourcing, which is a natural fit for eventual consistency, comes in.
Event sourcing provides a way to capture the events that occur in a system and store them in an Event Log. The log serves as the message broker and as the true record of what happened in the system, making it possible to replay events and restore the system to a previous state. This is a powerful tool for ensuring consistency in distributed systems and for improving the auditability and traceability of data changes.
The benefit of using an eventsourcing approch when designing an event driven system is that each domain event is persisted in the Event Log, and can be consumed by availible observers. And if necessery, be able to replay a process from a specific state.
By adopting Event Sourcing principles, software architects nd developers can ensure that the software they design or work on accurately refects the business domain. A separation of concerns is benefitial in system design, it ensures that each layer has a clear and specific responsibility. This makes it easier to develop and maintain the system, as each layer is semantically expressed, isolated - and if the process flows are not tightly coupled, then they can also be worked on independently.
In summary, adopting Domain-Driven Design principles and Event Sourcing for Process Design in software architecture can help simplify the design of complex business processes, ensure consistency in distributed systems, improve the auditability and traceability of data changes, and simplify the overall architecture by reducing dependencies and components. By adopting these principles, software architects can design software that is accurate, maintainable, and easily adapted to meet changing business needs.
Overview of the Superhero Tool Chain
The Superhero Tool Chain is a composition of several smaller components, including the Superhero Core Framework and the Superhero Eventsource component, as well as other components that are used to provide specific functionality for different use cases.
The Superhero Core Framework is a flexible and scalable backend framework that is built using Node.js. It provides a simple and efficient platform for building scalable and reliable software solutions, and includes several key components that are designed to work together seamlessly.
The Superhero Eventsource component is a key part of the tool chain, and is used to enable Event Sourcing in a clustered environment. It is built on top of Redis, which is a popular in-memory data store that is widely used for data caching and messaging. The eventsource component provides a simple and efficient way to capture events and store them in a Redis stream, allowing them to be consumed by available observers in the domain model.
The Superhero Tool Chain is designed to be flexible and modular, allowing developers to pick and choose the components that are most appropriate for their specific use case. This makes it possible to build software solutions that are tailored to the specific needs of each project, while still benefiting from the scalability and reliability of the underlying architecture.
The Superhero Tool Chain is designed to be lightweight and simplistisk, making it easier for the developers to adapt to different requirements and use cases. Its simplicity and efficiency makes it well-suited for developers that want to focus on the buissness and infrastructure logic. By using the Superhero Tool Chain, software architects can build reliable and scalable software solutions.
Understanding Event Sourcing
What is Event Sourcing?
Event sourcing is a design pattern that involves capturing all changes to an application’s state as a sequence of immutable events. Instead of storing the current state of the application, Event Sourcing stores a log of all the events that have occurred in the system. These events can then be replayed in order to restore the application’s state from a previous point in time.
In traditional CRUD-based (Create, Read, Update, Delete) systems, the application’s state is typically stored as a mutable entity, which is modified whenever a change is made to the data. However, this approach can be limiting, for a various of reasons… transactionally, traceability, etc…
With Event Sourcing, each change to the application’s state is recorded as an immutable event in the Event Log. The log can then be replayed in order to restore the state of the system to any point in time. This approach has several benefits:
-
Improved auditability and traceability: By capturing all changes to the application’s state, it becomes easier to track the changes that have been made to the data. This can help with debugging, testing, and ensuring compliance with regulations.
-
Flexible and scalable Process Design: Event Sourcing enables a more flexible and scalable approach to Process Design. Each event can be handled independently, and multiple processes can be designed to consume the same events.
-
Accurate representation of the domain: Event Sourcing will help ensure that the system accurately represents the business domain, by capturing each domain event in the Event Log.
Discussed further in detail: Benefits and drawbacks of Event Sourcing
Event Sourcing can be used in a wide range of systems, including banking systems, e-commerce systems, and content management systems. It is particularly useful in systems that require eventual consistency, where updates may occur concurrently across distributed nodes.
In this writing, we will explore in more detail how Event Sourcing works and how it can be applied in practice using the Superhero Tool Chain.
Why Use Event Sourcing in Process Design?
The Event Sourcing approach is well-suited for Process Design because it enables simplified process modeling, improved auditability and traceability of data changes, and the ability to easily modify and replay process flows.
When designing processes using Event Sourcing, developers can break down complex operations into smaller, simpler steps, each of which is executed in a consistent and predictable manner. This simplification of business logic can make it easier to understand, maintain, and adapt the software as business needs change.
The sequence of events captured through Event Sourcing can also serve as a detailed record of all data changes, enabling improved auditability and traceability of system changes. This record can be used to identify the root cause of issues, and to quickly restore the system to a previous state if necessary.
Another benefit of Event Sourcing in Process Design is the ability to easily modify and replay process flows. Since the events captured through Event Sourcing represent a complete history of all changes to the system, developers can easily replay these events to restore the system to a previous state or to test a modified process flow.
Event Sourcing is a technique for Process Design that enables simplified modeling, improved auditability and traceability, and the ability to easily modify and replay process flows. By adopting Event Sourcing principles, developers can design software that is both accurate and maintainable, and can be easily adapted to meet changing business needs.
How Event Sourcing works
In Event Sourcing, instead of storing the current state of the system, each individual event are recorded and used to calculate the current application state. This means that the application state can be changed if the processing of the Event Log is modified, even if the data is not. It also means that it’s possible to restore the system to any previous state by replaying the events in the correct order, to alter the execution of the process from.
At a high level, Event Sourcing works as follows:
-
The system captures domain events and adds them to an Event Log.
-
The system uses the events in the Event Log to build the current state of the system.
-
The system can allow users view the Event Log to improve tracability to unexpected outcomes.
-
The system can replay the events in the Event Log from a previous state, and/or modified previous state.
Transaction example
Here’s an example to help illustrate how Event Sourcing works. Let’s say we have a simple bank account application. Whenever a transaction occurs, the system records it as an event in the Event Log. Each event captures information about the transaction, such as the transaction type (e.g. deposit, withdrawal), the amount, and the date and time.
[
{
"timestamp" : "2007-11-23T13:11:55Z",
"domain" : "process/transaction",
"pid" : "abc-123",
"name" : "deposit",
"data" :
{
"amount" : 123.4
}
},
{
"timestamp" : "2007-12-05T12:01:42Z",
"domain" : "process/transaction",
"pid" : "abc-123",
"name" : "deposit",
"data" :
{
"amount" : 234.5
}
},
{
"timestamp" : "2007-12-22T10:25:18Z",
"domain" : "process/transaction",
"pid" : "abc-123",
"name" : "withdrawal",
"data" :
{
"amount" : 12.3
}
}
]
By capturing each transaction as an event, we can reconstruct the account balance at any point in time by replaying the events in the correct order. This makes it possible to audit the account and ensure that the balance is accurate at all times.
const domain = 'process/transaction'
const pid = 'abc-123'
const timestamp_from = 0
const timestamp_to = '2005-05-05T22:15:00Z'
const eventlog = await eventsource.readEventlog(domain, pid, timestamp_from, timestamp_to)
const balance = transaction.calculateBalance(eventlog)
Where the calculateBalance function has logic that could look something like the following…
calculateBalance(eventlog)
{
let balance = 0
for(const event of eventlog)
{
switch(event.name)
{
case 'deposit':
balance += event.data.amount
break
case 'withdrawal':
balance -= event.data.amount
break
default:
throw new Error('unrecognized transaction type supplied')
}
}
return balance
}
E-commerce example
Let’s consider an additional example to further illustrate Event Sourcing. Let’s say we have an e-commerce application that allows users to place orders for products. The system captures each order as an event in the Event Log, along with information about the order, such as the customer’s name, address, and payment information.
[
{
"timestamp" : "2011-07-11T18:35:08Z",
"domain" : "process/workorder",
"pid" : "12345-XYZ",
"name" : "created",
"data" :
{
"order" :
{
"total": 100
"articles":
[
123,
231,
312
]
}
}
},
{
"timestamp" : "2011-07-11T18:35:12Z",
"domain" : "process/workorder",
"pid" : "12345-XYZ",
"name" : "discount",
"data" :
{
"coupon" : "a-12345"
}
},
{
"timestamp" : "2011-07-11T18:35:30Z",
"domain" : "process/workorder",
"pid" : "12345-XYZ",
"name" : "payed",
"data" :
{
"billing" :
{
// ...
}
}
},
{
"timestamp" : "2011-07-11T18:35:30Z",
"domain" : "process/workorder",
"pid" : "12345-XYZ",
"name" : "shipping address",
"data" :
{
"shipping" :
{
"name" : "John Doe",
"address" : "Some street name and number, City, Country"
}
}
},
{
"timestamp" : "2011-07-11T18:35:31Z",
"domain" : "process/workorder",
"pid" : "12345-XYZ",
"name" : "shipping address validated",
"data" :
{
"shipping" :
{
"address-id" : 34567
}
}
},
{
"timestamp" : "2011-07-12T16:24:12Z",
"domain" : "process/workorder",
"pid" : "12345-XYZ",
"name" : "shipped",
"data" :
{
"shipping" :
{
"tracking-id" : "abc-123-456-789"
}
}
}
]
By capturing each order as an event, we can reconstruct the order history for a specific customer at any point in time by replaying the events in the correct order. This allows us the possibility to retry a failed order flow that broke, for instance becouse of a delivery problem, where we design a process flow that declares that if the address is updated then the package will be sent out again reusing the same event flow.
[
// ...
{
"timestamp" : "2011-07-12T16:24:12Z",
"domain" : "process/workorder",
"pid" : "12345-XYZ",
"name" : "shipped",
"data" :
{
"shipping" :
{
"tracking-id" : "abc-123-456-789"
}
}
},
{
"timestamp" : "2011-07-16T08:05:10Z",
"domain" : "process/workorder",
"pid" : "12345-XYZ",
"name" : "incident",
"data" :
{
"incident" :
{
"description" : "Could not deliver"
}
}
},
{
"timestamp" : "2011-07-17T16:14:42Z",
"domain" : "process/workorder",
"pid" : "12345-XYZ",
"name" : "shipping address",
"data" :
{
"shipping" :
{
"name" : "John Doe",
"address" : "Some other street name and number, City, Country"
}
}
},
// ...
]
Conclusion
Event Sourcing makes it possible to make changes to the application’s behavior without losing the historical data. Let’s say that we want to change the way orders are processed in the system. With Event Sourcing, we can create a new version of the order processing logic and conclude a new application state while still retain the historical data captured in the Event Log.
In summary, in Event Sourcing, by capturing each change as an event, it becomes possible to reconstruct the application’s state at any point in time, and to make changes to the system behavior without losing historical data. This is a powerful tool for ensuring consistency in distributed systems, improving the auditability and traceability of data changes, and enabling simpler and more flexible Process Design.
Benefits and drawbacks of Event Sourcing
Event Sourcing provides several benefits for software architecture and Process Design, but it also has some drawbacks. Here are some of the key benefits and drawbacks of using Event Sourcing:
Benefits
-
Improved auditability and traceability of the data: By recording every change to an application’s state as a sequence of immutable events, Event Sourcing enables a clear and accurate record of every change made to the data. This can be particularly useful in regulated industries, such as finance and healthcare.
-
Simplification of Process Design: Event Sourcing enables breaking down complex operations into smaller, simpler steps, making it easier to understand, maintain, and adapt the software as the business changes. This simplification of business logic can also make it easier to model complex business domains.
-
Improved scalability: Because Event Sourcing stores data in an Event Log on which the system can be designed to consume these events by a multitude of observable processes, this leads to the ability of horizontal scaling, through adding on observable nodes to the cluster.
-
Replay functionality: Event Sourcing makes it possible to replay events and from a previous state, or restore the system to a previous state, which can be useful in scenarios such as auditing, testing, or debugging.
-
Separation of concerns: Event Sourcing provides a clear separation between the domain model and the persistence mechanism, making it easier to develop and maintain the system.
Drawbacks
-
Increased complexity: Event Sourcing adds some complexity to the system, as every write operation has to be treated as a separate event and stored in the Event Log. This makes it slower to develop the system; as more specifications and seperations is required to define the logic segment.
-
Increased storage requirements: Event Sourcing requires storing every change to the system’s state, which can result in a larger storage requirement than traditional persistence mechanisms.
-
Eventual consistency: With Event Sourcing, the data is eventually consistent, which means that there will be some latency between the time an event is recorded and the time it is available for use. This latency can create issues for certain systems that require immediate or synchronous data access.
-
Limited querying capabilities: Because the data is stored in an Event Log, querying the data can be more complex than with traditional databases, and there may be a learning curve associated with understanding the structure of the Event Log.
Solving the limited querying capabilities in the read model
In regards to the limited querying capabilities that exists in Event Sourcing, the Event Log is designed primarily for writing data rather than reading it. However, this challenge can be overcome by separating the read and write models in the system architecture.
In this design approach, the Event Log is used soley as the write model, while the read model is maintained separately for querying purposes. The read model is updated based on the events captured in the Event Log, providing a materialized view of the system’s data that can be efficiently queried.
By using a separate read model, the system can easily support complex queries and reporting requirements without sacrificing the benefits of Event Sourcing. This approach also allows for the creation of optimized data structures and indexing techniques for querying, resulting in faster and more efficient data retrieval.
Separating the read and write models can help overcome the limited querying capabilities of Event Sourcing. By adopting this approach, developers can ensure that their system benefits from the advantages of both Event Sourcing and traditional querying techniques, resulting in a more flexible and efficient architecture.
Understanding Event Storming
What is Event Storming?
Event Storming is a collaborative workshop technique that helps teams understand and design complex systems and processes. It was introduced by Alberto Brandolini as a way to break down the traditional silos between business and technical teams and to foster a shared understanding of the business domain.
At its core, Event Storming is a visual and interactive approach to Domain-Driven Design that allows teams to model business processes and domains by capturing events and business logic. This technique is often used in conjunction with other Domain-Driven Design practices, such as bounded contexts and composition of the ubiquitous language, to create a clear, shared language between all stakeholders.
Performing an Event Storming session
Event Storming is typically done in a group setting, with team members from different roles and departments, including business analysts, developers, and domain experts. The process starts by defining the goal of the session, which is usually a business process that needs to be analyzed or a new feature that needs to be designed.
In Event Storming, elements are defined by different colors to indicate the specific type of a domain concept or event that is captured during the Event Storming session.
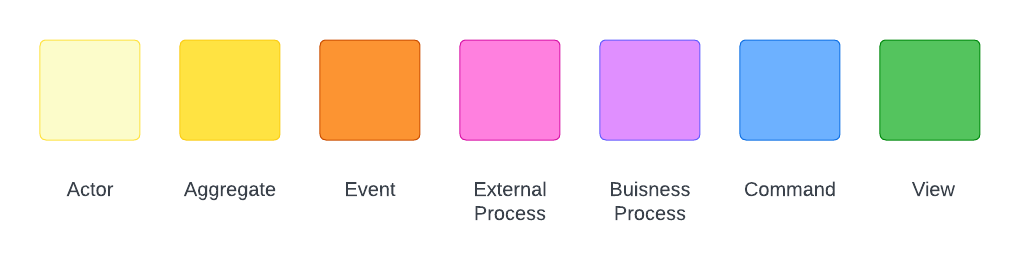
The colors are used to represent different categories of events and concepts, such as commands, aggregates, external systems, and more. These colors help to visually differentiate between the different types of concepts and events, making it easier to understand the domain model that is being developed during the session.
The colors used in Event Storming can vary depending on the facilitator, how I describe it - the next facilitator may not, but the colors generally follow a similar pattern.
The group then works together to identify and define the events that occur during the process, including the triggers that cause the events to happen, the entities involved, and the actions mapped as a response of each event, if any action is expected. The events are often visualized on a wall or whiteboard using sticky notes or other visual aids, allowing the team to see and interact with the events as they are developed.
The resulting model created during the Event Storming session can then be used as a basis for creating user stories, use cases, and other design artifacts that can be used to develop the software. It provides a shared understanding of the business domain that can help to ensure that the software meets the needs of all stakeholders.
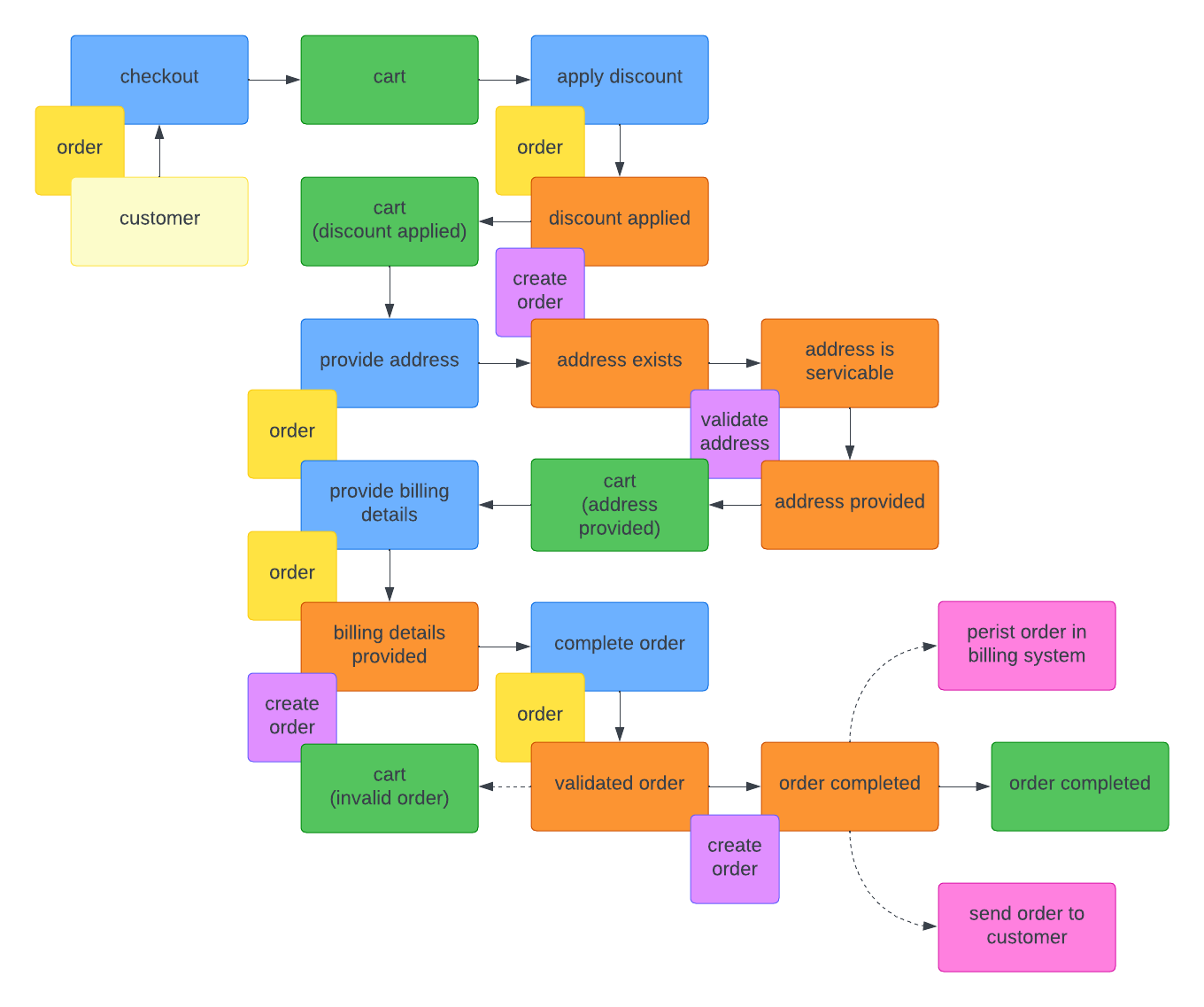
The image above shows a part of an Event Storming session for an e-commerce system, specifically the checkout process flow to complete an order.
Event Storming is a valuable technique for any team involved in the design and development of more complex systems and processes. It fosters collaboration, shared understanding, and a focus on business value, making it a suitable practice for anyone working on code in collaboration with others.
How to Use Event Storming for Process Design
Event Storming is a collaborative process that can be used to design, model, and improve business processes. Here are the key steps involved in using Event Storming for Process Design:
Step 1: Identify the Business Process to be Designed
The first step in using Event Storming for Process Design is to identify the specific business process that you want to model. It’s essential to focus on a specific process that you want to improve, rather than trying to model the entire business at once. This approach helps you to stay focused and make progress quickly.
Step 2: Define the Scope and Goals of the Process
Once you have identified the business process to be designed, define the scope and goals of the process. This helps you to stay focused and relevant to the task at hand and ensures that you are designing a process that meets the specific needs of the business. While conducting the session, avoid drifting away from the business core and focus on urgent and essential needs.
Step 3: Assemble a Diverse Group of Stakeholders
Event Storming is a collaborative process, so it’s crucial to gather a diverse group of stakeholders to participate in the session. This group can include domain experts, business analysts, developers, and other stakeholders who have an interest in the process being designed.
Step 4: Conduct an Event Storming Session
The heart of Event Storming is the actual session, which is typically conducted using a large, physical wall, whiteboard or virtually using software tools. The session is led by a facilitator who guides the group through the process of creating a visual representation of the business process.
The session typically starts by identifying the end of the process, the “process completed” event, followed by identifying the “trigger” events that initiate the process, then moving on to identify the actions and other events that occur throughout the process. Each event is represented on the wall using sticky notes or index cards, and the group works together to organize the events in a way that makes sense, using arrows and other symbols to show the flow of the process. The end result is a visual representation of the business process.
Step 5: Refine the Process and Identify Opportunities for Improvement
Once the visual representation of the process has been created, it’s crucial to review the process and identify opportunities for improvement. This can include identifying bottlenecks, inefficiencies, and areas where the process can be automated. The process can also be reviewed by stakeholders for feedback and possible changes.
Step 6: Create a Formal Process Model
Once the process has been refined and improved, it’s essential to create a formal process model that can be used to guide the implementation of the process. This concludes creating a flowchart as a visual representation of the isolated process that declares the command and event flow in particßular.
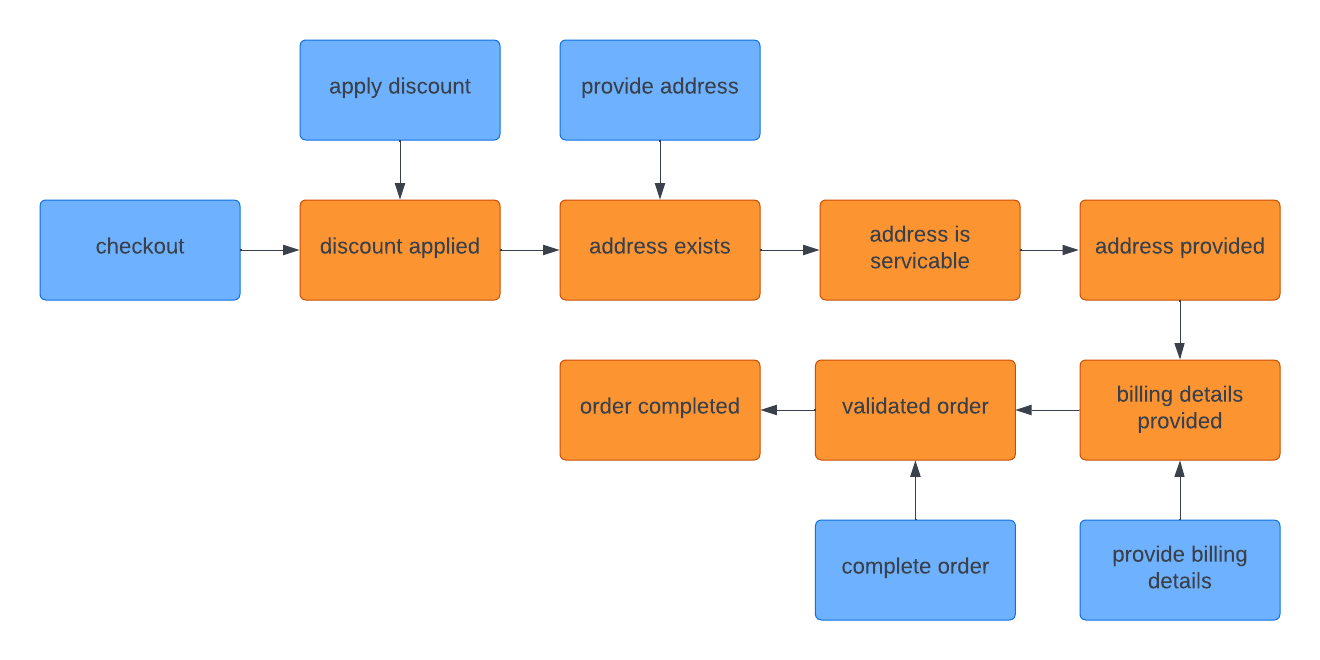
A process model should be both defined and implemented in isolation, as a separate observer and dispatcher model, that depends on aggregates to perform or dispatch commands. Learn about implementing observer and dispatcher models in the chapter: Creating a new project with the Superhero Eventsource
Step 7: Implement and Refine the Process
The final step is to implement the process and improve on it over time. The expectation is on using the Event Storming model to guide changes required by stakeholders in the implemented process model.
By following these steps, businesses can use Event Storming to design, model, and improve their business processes, resulting in more efficient and effective operations due to transparency into what is intended to happen, what happened, when it happened, and with proper error logging - then also “why” it happened.
Benefits of using Event Storming for Process Design
While Alberto Brandolini did not specifically mention the concept of Process Design in his original concept of Event Storming, the Event Storming technique expresses explicit process models as a result of a successfull session. Event Storming is therefor a benefitial approch to Process Design.
Event Storming is a technique that can be used to design and model business processes. By involving different stakeholders, simplifying Process Design, and aligning with business needs, Event Storming can result in more effective and efficient processes. Additionally, by integrating with Event Sourcing, full transparency into how the process flow was implemented is offered, and a more accurate and effective process model can be defined.
Let’s go through some of the key benefits of using Event Storming for Process Design.
Collaboration and engagement with stakeholders
Event Storming enables stakeholders to collaborate and contribute their knowledge and expertise to the Process Design, resulting in a more comprehensive and effective process model. By bringing together people from different backgrounds, the Process Design should align better with business needs and goals as a result.
Alignment with business needs
Event Storming can help ensure that the process model aligns with the specific needs and goals of the business. By involving stakeholders from different departments and disciplines, the resulting process model can be more relevant and effective for the organization.
Simplification of Process Design
Event Storming helps to simplify Process Design by breaking down complex operations into smaller, simpler steps, making it easier to understand, maintain, and adapt the software as the business changes. This simplification of business logic should also make it easier to model complex business domains and processes.
Improved transparency and continuous improvement
The visual representation of the process model created during an Event Storming session offers improved transparency into how the process should be implemented. This helps stakeholders to understand the process flow and make requests for modifications, leading to continuous improvement and optimization of the process.
Integration with Event Sourcing
While Event Storming expresses the blueprints of how the process should be implemented, Event Sourcing offers transparency into what concretely happened in the system. This integration can help to improve the accuracy, as well as help improve the effectiveness of the process model.
Getting Started with the Superhero Tool Chain
The name “Superhero” was chosen to reflect the unrealistic expectations often placed on developers. Not only are developers expected to handle full-stack development and DevOps, but they are also expected to design, architect, and manage the development cycle. In essence, businesses need a superhero, and the Superhero Tool Chain is designed to help developers meet those expectations.
Explanation of the Superhero Tool Chain
The Superhero Tool Chain is a lightweight and easy-to-use toolset that can help developers implement event-driven systems using Event Sourcing. It simplifies the process of creating such systems by providing a set of tools and patterns that are easy to understand.
Components of the Superhero Tool Chain
At the heart of the Superhero Tool Chain is the “Superhero Core” framework. This framework helps developers segregate responsibilities into services, and contain a set of reusable utility components, that are not specifically covered in this writing.
The Superhero Tool Chain also includes the “Superhero Eventsource” component, which facilitates the implementation of event-driven systems using Event Sourcing. The “Superhero Eventsource” component processes and consumes events using Redis as a storage backend.
Above described components are the specific components that are used to solve the design requirements discussed in this writing. However, the Superhero Tool Chain includes several other tools that may be of interest:
Creating a new project with the Superhero Core Framework
Before getting started with the Superhero Tool Chain, you’ll need to set up a new project. This chapter will walk you through the steps to create a new project using the Superhero Tool Chain.
Prerequisites
You’ll need to have Node.js installed on your machine. You can download and install Node.js from the official website.
Initializing a New Project
To create a new project, you can use the npm init command to initialize a new Node.js project. This will create a new package.json file in your project directory.
npm init -y
Once you’ve created the package.json file, you can install the Superhero Core Framework by running the following command:
npm install superhero --save
This will install the superhero package and save it as a dependency in your project’s package.json file.
Setting up the Superhero Core Framework
Next, you’ll need to set up the Superhero Core Framework in your project. To do this, you’ll need to create a main file in your project directory, and add the following code:
const
CoreFactory = require('superhero/core/factory'),
coreFactory = new CoreFactory,
core = coreFactory.create()
core.add('app', __dirname)
core.load()
core.locate('core/bootstrap').bootstrap().then(() =>
{
core.locate('core/console').log('app loaded...')
})
This code imports the superhero/core/factory module and creates a new instance of the CoreFactory. It then creates a new core instance using the create method, and adds the app configuration to the core using the add method. The load method is then called to load the configuration, followed by the bootstrap method to run through all configured bootstrap services. Finally, a message is logged to the console to indicate that the app has loaded.
Configure the Superhero Core Framework
Each added core component is expected to define a configuration, that more or less can look however, as long as it’s described as a JS object. Many configurations can be made, depending on the use, but here we will only go through the basics:
module.exports =
{
core:
{
bootstrap:
{
'foobar': 'app/some-service'
},
locator:
{
'app/some-service': __dirname + '/some-service'
}
}
}
In this basic example, the foobar bootstrap process is located in the specified directory path __dirname + '/some-service', relative to the configuration file. The locator property maps this service to its file path. This configuration tells the core to eager load the specified service when the project starts up, utelizing an expected locator instance declared in that specifed directory path.
Locating a Service in the Superhero Core Framework
The Superhero Core Framework utelizes the service locator pattern to locate services in the system by using a central registry of services. When a service is needed, it is not created but rather located, already constructed, through a service locator.
If you dislike the idea of using a service locator in your system design, please read the notation I made regarding using a service locator in system design.
To make it possible to locate a service in the Superhero Core Framework, start by creating a new subdirectory with the name of the service you want to create. Inside this subdirectory, create a file named locator.js responsible for creating and locating the service’s dependencies.
Here’s an example of what the locator.js file might look like:
const
SomeService = require('.'),
LocatorConstituent = require('superhero/core/locator/constituent')
class SomeServiceLocator extends LocatorConstituent
{
locate()
{
const console = this.locator.locate('core/console')
return new SomeService(console)
}
}
module.exports = SomeServiceLocator
In this example, the SomeService class is imported from the same directory (indicated by the . character), and the core/console component is located and dependency-injected on constructing the service on the next line.
Bellow is an example of what the service class could look like, declared in the index.js file of the service subdirectory.
class SomeService
{
constructor(console)
{
this.console = console
}
bootstrap()
{
this.console.log('bootstrap process...')
}
}
module.exports = SomeService
As described in the configuration file, the SomeService class is expected to respond to the bootstrap interface by implementing a bootstrap method in the service.
Conclusion
The final file structure should look like this:
app
├── src
│ ├── some-service
│ │ ├── index.js
│ │ └── locator.js
│ ├── app.js
│ └── config.js
└── package.json
When you start the solution, the terminal output should now end with the message bootstrap process..., followed by app loaded..., in the correct order, indicating that the bootstrap process has completed and the app has been loaded successfully.
This message sequence lets you know that the app is ready to use, and in what order the code was processed.
Creating a new project with the Superhero Eventsource
To use the Superhero Eventsource component in a new project, it needs to be added to the core context by invoking the core.add method with the following arguments: eventsource/client and @superhero/core.eventsource/src/client.
The full content of the main file would then look like this:
const
CoreFactory = require('superhero/core/factory'),
coreFactory = new CoreFactory,
core = coreFactory.create()
core.add('eventsource/client', '@superhero/core.eventsource/src/client')
core.add('app', __dirname)
core.load()
core.locate('core/bootstrap').bootstrap().then(() =>
{
core.locate('core/console').log('app loaded...')
})
It’s important to note that the order in which the components are added to the core context matters becouse of the hierarchy of configurations, if there are conflicting configurations in the different componenets. Often the configurations needs to be overwritten, as described in below example.
Configuring the Superhero Eventsource
The Superhero Eventsource has some configurations that should be set. Here’s an example of what the configuration file might look like:
module.exports =
{
core:
{
// ...
},
client:
{
eventsource:
{
auth : 'optional-and-if-needed',
domain : '*',
name : '*',
gateway:
{
url: `redis://127.0.0.1:6379`
}
}
}
}
In the configuration, a new segment called client is added as a sibling to the core scope, and an eventsource scope is defined within the client scope.
- The auth attribute is used to provide an AUTH password to Redis, if needed.
- The domain attribute configures the solution to observe events related to a specific domain. The asterisk
*value indicates that all domains are being observed. - The name attribute configures the solution to observe specific events by a specific name. The asterisk
*value indicates that all event names are being observed. - The gateway scope declares a url attribute that is used to define the endpoint on where the Redis server can be reached.
Locate the Superhero Eventsource component
Continuing on from the previous example, we can locate the eventsource client in the SomeServiceLocator and inject it into the SomeService instance during construction.
const
SomeService = require('.'),
LocatorConstituent = require('superhero/core/locator/constituent')
class SomeServiceLocator extends LocatorConstituent
{
locate()
{
const
console = this.locator.locate('core/console'),
eventsource = this.locator.locate('client/eventsource')
return new SomeService(console, eventsource)
}
}
module.exports = SomeServiceLocator
In the above example, the SomeService is injected with the eventsource client located from the client/eventsource namespace. The SomeService class declares an observer for the foo event, which is persisted during the bootstrap process, and another observer for the bar event, which is persisted within the foo observer.
class SomeService
{
constructor(console, eventsource)
{
this.console = console
this.eventsource = eventsource
}
async bootstrap()
{
this.console.log('bootstrap process...')
const
domain = 'app/some-service',
pid = 'abc123',
name = 'foo',
data = { some:'value' }
await this.eventsource.write({ domain, pid, name, data })
}
onFoo(event)
{
this.console.log('foo...')
const name = 'Bar'
await this.eventsource.write({ name }, event)
}
onBar(event)
{
this.console.log('bar...')
}
}
module.exports = SomeService
In the example provided, the bootstrap process utelizes the eventsource component to save an event that specifies a domain. The domain maps to the service names in the configuration file for the Superhero Core Service Locator component. This mapping is resolved back to the class SomeService due to the specified domain value: app/some-service. As a result, the SomeService instance can observe the saved event, enabling the instance to react to it.
In the foo observer, the observed event is passed along when writing a new event to the eventsource. This chains the event to the previous metadata (domain and pid), but with a new name for the event: bar.
What Happens When Events are Persisted in the Superhero Eventsource
The eventsource component is responsible for persisting the event in a Redis Stream (and in some other Redis structures for indexation and key-value distribution). After the event is persisted, the component publishes a message over Redis Pub/Sub to indicate that the Stream has been written to, with a new event, that specifies a domain and event name. The client observes the published message and dispatches a consumer to consume the event from the Redis Stream.
Conclusion
Adopting the consumer approach for persisted events enables horizontal scaling in a clustered environment, which is especially useful for systems that prioritize eventual consistency. By increasing the replication state of the service in the orchestration, more nodes can share the workload of different processes and work in parallel. This approach helps prevent the flow of sibling processes with queued messages from being locked, improving the overall efficiency and performance of the system.
Notations regarding the Superhero Tool Chain
Notation regarding using a service locator
While the service locator pattern can be useful for decoupling components, it is often criticized for encapsulating a global state and making it difficult to understand a component’s dependencies which the service locator is injected into. In does cases, dependencies are not explicitly stated and it becomes unclear what is required for the component to function. This is similar to issues that is depending on static or global definitions in an system.
One solution is to restrict the implementer to pass the service locator to the class it initiates. Although it is possible to use that approach, it is generally considered a bad practice and should be avoided.
Implementing Event Sourcing like a Superhero
When implementing a Process Design from an Event Storming session, the “Superhero Tool Chain” offers a lightweight solution to simplify the process between design and implementation.
Creating a Process Design flowchart from an Event Storming session
As earlier described, Event Storming is a technique for identifying the essential events and processes of a system. But, once you’ve identified these events, the question is how to turn the discivery into a concrete Process Design?
In this article, we’ll show you how to transform the results of an Event Storming session into a Process Design flowchart. By following this approach, you can gain a clear understanding of the processes and events that make up your system, and develop according to the blueprints for the implementation.
How to Transform an Event Storming Session to a Process Design Flowchart
To create a Process Design flowchart from an Event Storming session, follow these steps:
- Identify the essential events, commands in the processes of the system using Event Storming.
- Map the events and processes onto a Process Design flowchart, using swimlanes to represent the different types of processes.
- Reduce the noise from the Event Storming session be ignoring details such as the identified actors, aggregates and inputs and outputs of each process.
- Validate the Process Design flowchart with stakeholders, expressed in isolation, and domain experts to ensure that the flowchart accurately reflects the system.
Refining and iterating over the Process Design flowchart should be avoided, as this itterations for improvements should be done on the result of the Event Storming session. The responsibility of the Process Design flowchart is only to reflect the Event Storming session.
By representing the Process Design as described above, the flowchart will accurately represents the essential events, commands and processes of the system. The Process Design flowchart should serve as a blueprint for the implementation of your system, guiding developers on the process flow in the eventual concistency model of the implementation.
In conclusion, Event Storming is a technique for identifying the domain model, including essential events, commands and processes of the system. The Process Design flowchart is a flowchart composed only of the essential events, commands and processes of the system that ios expressed by the Event storming session. The Process Design flowchart expresses an isolated and more superficial understanding of the system that acts as the blueprint for the Process Design implementation.
Transforming an Event Storming Session into a Process Design Flowchart
Event Storming is a technique for identifying essential events and processes in a system. Once these have been identified, the next step is to turn the results of an Event Storming session into a concrete Process Design flowchart that developers can use as a blueprint for implementing the eventual consistency model.
In this article, we will explain how to transform the results of an Event Storming session into a Process Design flowchart. By following this approach, you can gain a clear understanding of the processes and events that make up your system and develop accordingly.
How to Transform an Event Storming Session to a Process Design Flowchart
To create a Process Design flowchart from an Event Storming session, follow these steps:
- Identify the essential events and commands in the system’s processes using Event Storming.
- Map the identified events and processes onto a Process Design flowchart, using swimlanes to represent the different types of processes.
- Eliminate the noise from the Event Storming session by disregarding details learned in the session, such as the identified actors, aggregates, and the IO of each process.
- Validate the Process Design flowchart by comapring it to the Event Storming session to ensure that the flowchart accurately reflects the system design.
It’s important to note that refining and iterating over the Process Design flowchart should be avoided. Improvements should be made on the results of the Event Storming session. The responsibility of the Process Design flowchart is to reflect the Event Storming session accurately.
By representing the Process Design according to above stated policies, the flowchart will accurately reflect the Process Design of the system. The Process Design flowchart should serve as a blueprint for the implementation of the eventual consistency model of the system.
Key takeaway
Event Storming is a technique for identifying the domain model, including essential events, commands, and processes of the system. The Process Design flowchart is a flowchart composed only of the essential events, commands, and processes of the system expressed by the Event Storming session. The Process Design flowchart expresses an isolated and more superficial understanding of the system that acts as the blueprint for the Process Design implementation.
Modeling the domain in the Superhero Core Framework
To implement the flowchart in the Superhero Core Framework, we can follow these steps:
- Create a domain folder in the project
- Create a subfolder in the domain folder for each aggregate root identified
- In each subfolder representing an aggregate root, add the files:
ommand.js,query.jsandlocate.js - Create a process folder in the project, next to the domain folder
- Create a subfolder in the process folder for each process identified
- In each subfolder representing a process flow, add the files:
index.jsandlocate.js - Identify the events of the process and name them in the process class with the naming convention “foo bar” to the interface implementation
onFooBar(event) - Identify the commands of the process and name them in the command class of the aggregate, following the naming convention: “bar baz” to the interface implementation
barBaz(command) - Depend on the dependent aggregates and map the correlated commands in the observers of the flow
- In each observer, after the commands are dispatched, persist that fact as an event in the eventsource, for the next step to be observed and dispatched
Processing events using the Superhero Eventsource component
Following is an example of how a Process Design can be implemented using the Superhero Tool chain.
If we have a Process Design for the Foo entity that looks something like create ➞ created ➞ index ➞ indexed.
Then in the domain folder, in the foo subfolder, in the command.js file, it’s expected to reflect the below command model:
class FooCommand
{
// ...
async create(command)
{
const
domain = 'process/create-foo',
pid = 'abc123',
name = 'created',
data = { command }
return await this.eventsource.write({ domain, pid, name, data })
}
async index(command)
{
return await this.mysql.createFoo(command)
}
}
module.exports = FooCommand
In the process folder, create a subfolder for each process identified. In this case, we’ll create a create-foo subfolder.
In the create-foo subfolder, add the files index.js and locate.js. The index.js file should implement the ProcessCreateFoo class, which has the onCreated and onIndexed observer methods.
Resulting in an eventual consistency model located in the process folder, that is expected to have a subfolder called create-foo that has an index.js, as shown below:
class ProcessCreateFoo
{
// ...
async onCreated(event)
{
const indexed = await this.foo.index(event.data.command)
const name = 'indexed'
const data = { indexed }
return await this.eventsource.write({ name, data }, event)
}
async onIndexed(event)
{
const processState = await this.eventsource.readState(event.domain, event.pid)
console.log('process completed, foo entity created', processState)
}
}
module.exports = ProcessCreateFoo
Once the Foo command and the ProcessCreateFoo observer are implemented, we can depend on the dependent aggregates and map the correlated commands in the observers of the flow.
In the observer, after the commands are dispatched, persist an event in the eventsource that descibes the event that occured for the next step to be able to observe the process taken place and dispatch the next commands.
By following the outlined steps and using code examples, developers are intended to be able to create maintainable and scalable codebases that accurately reflect the processes and events within the system.
Replay functionality using the Superhero Eventsource component
One of the advantages of using an Eventsource approch is the ability to create replay functionality in a processes. This is done by persisting an event in the eventsource by the name of the observer in the eventual consistency model that is to be replayed. Once the event is saved, the observer can observe it and dispatch the next step in the process flow.
While persisting this replay event, it’s possible to do 1 of 2 things:
- Persist the event aligned to how the event was persisted the first time, simply retrying the same event process again - with the same data, often useful if an upstream error or bug in the code processing the event observer.
- Persist the event with new data, different to how the event was persisted the first time. This is a useful approch for when the process flow was currupted, and the data requires to be updated to be able to complete the process.
Replay functionality is valuable when dealing with broken process flows. By replaying the events in the correct order, it’s possible to bring the system back to its correct state. This can save a significant amount of time and effort compared to manually fixing the broken process flow.
Replay functionality is a valuable tool that can be used to heal broken process flows and prevent errors from terminating the automation.
Last Gasp
Summary of key points
The Superhero Tool Chain simplifies the implementation of a resulting Event Storming session, a collaborative workshop technique that helps teams better understand complex business domains and design effective software solutions. The Superhero Tool Chain provides a straightforward solution for building event-driven architectures, allowing developers to translate an Event Storming session into a Process Design flowchart that represents the system’s processes and events.
The Superhero Tool Chain provides a reliable, scalable, and fault-tolerant solution that’s crucial for modern software development. By adhering to the segregation of concerns principle, the Superhero Tool Chain enables developers to create maintainable and scalable code that’s easier to test and deploy.
The Superhero Eventsource component is a lightweight solution for implementing Event Sourcing, a design pattern that allows developers to persist events and reconstruct the system state at any point in time. Implementing Event Sourcing improves system scalability and testing capabilities, making it easier to manage large volumes of data and events. By utelizing Event Sourcing, developers can create systems with improved traceability and monitoring capabilities, which is especially valuable in critical business systems.
With the Superhero Eventsource component, developers can easily implement replay functionality for process flows, allowing them to quickly recover from process errors and help maintain the systems integrity. The Superhero Core Framework and Eventsource component provide a flexible solution for building event-driven architectures that can seamlessly scale to meet the demands of complex, data-intensive systems without the overhead that larger similar solutions require.
Read more
To any software developer or architect, the book: ‘Domain Driven Design: Tackling Complexity in the Heart of Software’ by Eric Evans is an essential resource. In this book, Eric Evans introduces a design approach that focuses on modeling the domain of the business problem at hand, rather than solely relying on technology-based solutions. This methodology can help developers create more maintainable and scalable software systems.
Another recommended read is ‘Introducing EventStorming: An Act of Deliberate Collective Learning’ by Alberto Brandolini. This book introduces the practice of EventStorming, a workshop technique that allows developers and stakeholders to collaboratively explore complex business domains and design effective software solutions.
While Greg Young, at least to my knowledge, has not published any books on Event Sourcing or CQRS, he has given several talks on these topics that are worth checking out. Event Sourcing and CQRS are related design patterns that can be used to improve scalability, performance, and fault tolerance in software systems, as described in this writing.
Finally, I would recommend watching Martin Fowler’s talk on ‘The Many Meanings of Event-Driven Architecture’, which he delivered during the GOTO 2017 conference. In this talk, Martin Fowler discusses the benefits and challenges of designing event-driven architectures, where events are used as the primary means of communication between components.
Benefits of using the Superhero Tool Chain for process design
The Superhero Tool Chain provides numerous benefits for process design from the perspective of simplicity and being lightweight.
For individuals or small teams who are responsible for managing and taking responsibility for all layers of a system, the Superhero Tool Chain offers a solution to make it easier to handle that responsibility. Its design makes it an ideal choice for those who need to quickly and efficiently design and implement processes without extensive configuration or customization of the ecosystem supporting the system.
The Superhero Eventsource component offers a simple process design that makes it possible to replay events and “heal” broken process flows. This ensures that processes can be restored quickly and effectively, even in the event of an unexpected failure.